ThreadPoolExecutor线程池 实现原理
类结构
首先要先了解一下类结构,如下图:
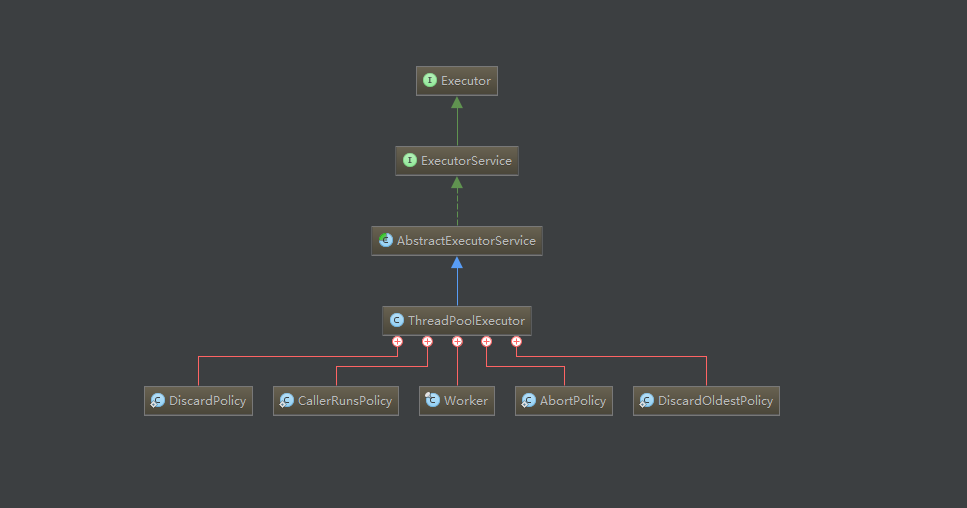
Executor
|
|
只有一个接口,传入一个Runnable对象,线程池就会帮你执行这个指令。
ExecutorService
|
|
这个接口是执行器服务接口,声明了关于执行器的许多管理方法。
AbstractExecutorService
|
|
这个抽象类实现了ExecutorService接口中的大部分方法,不过大部分的实现都依赖于Executor接口声明的execute方法,而这里并没有实现这个关键的方法,而是把这个方法的实现交给了子类,也就是java.util.concurrent.ThreadPoolExecutor来实现了。