ThreadPoolExecutor线程池 实现原理
类结构
首先要先了解一下类结构,如下图:
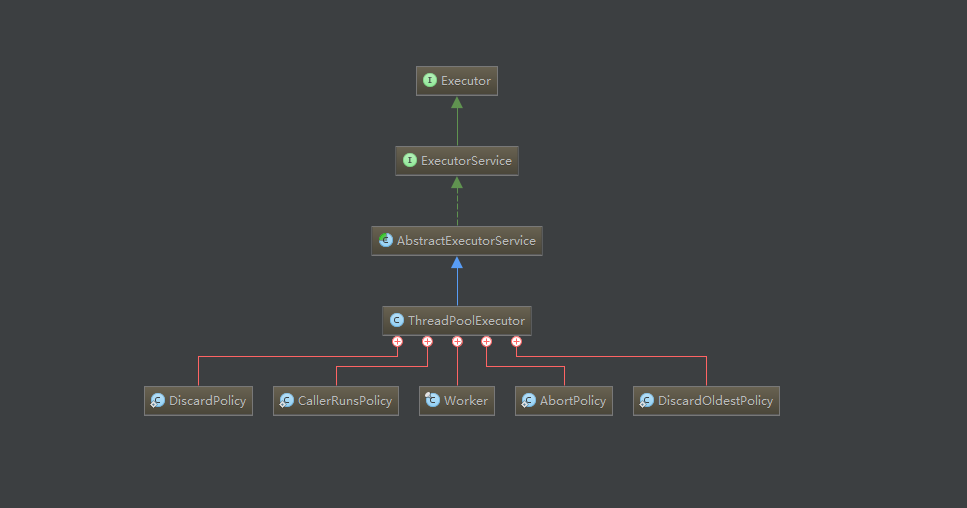
Executor
|
|
只有一个接口,传入一个Runnable对象,线程池就会帮你执行这个指令。
ExecutorService
|
|
这个接口是执行器服务接口,声明了关于执行器的许多管理方法。
AbstractExecutorService
|
|
这个抽象类实现了ExecutorService接口中的大部分方法,不过大部分的实现都依赖于Executor接口声明的execute方法,而这里并没有实现这个关键的方法,而是把这个方法的实现交给了子类,也就是java.util.concurrent.ThreadPoolExecutor来实现了。
Worker
|
|
Worker,每一个Worker对象代表了一个线程,同时也是真正负责执行任务的对象。
构造方法
|
|
corePoolSize:核心池的大小,在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。只有当工作队列满了的情况下才会创建超出这个数量的线程。如果某个线程的空闲时间超过了活动时间,那么将标记为可回收,并且只有当线程池的当前大小超过corePoolSize时该线程才会被终止。用户可调用prestartAllCoreThreads()或者prestartCoreThread()方法预先创建线程,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;当大于了这个值就会将Thread由一个丢弃处理机制来处理。keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;Unit:参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性。workQueue:一个阻塞队列,用来存储等待执行的任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。threadFactory:线程工厂,主要用来创建线程;handler:表示当拒绝处理任务时的策略,也就是参数maximumPoolSize达到后丢弃处理的方法。有以下四种取值:
|
|
用户也可以实现接口RejectedExecutionHandler定制自己的策略。
实现原理
按照下面的几个方面来阅读jdk的源码:
- 线程池的状态
- 线程任务执行
- 线程池关闭
- 线程容量动态调整
线程池的状态
跟线程池状态有关的几个属性:
|
|
ctl:标识线程池当前状态和线程数的,这里要特别注意,这个属性把两个变量打包成一个变量了,通过这个属性可以计算得出目前的线程数和线程池当前的状态。RUNNING:正在处理任务和接受队列中的任务。SHUTDOWN:不再接受新的任务,但是会继续处理完队列中的任务。
STOP:不再接受新任务,也不继续处理队列中的任务,并且会中止正在处理的任务。
TIDYING:所有任务都已经处理结束,目前worker数为0,当线程池进入这个状态的时候,会调用terminated()方法。
TERMINATED:线程池已经全部结束,并且terminated()方法执行完成。
线程任务执行
|
|
首先判断了传入的指令对象是否为空,为空就不用执行了,直接抛出异常。如果指令对象不为空,那么就真正进入线程任务的逻辑,一共分为3步来处理:
- 检查当前线程总数,如果低于核心线程数,则创建新的线程来执行这个任务
|
|
这里workerCountOf(c)可以从计数器(clt)的结果中计算出当前线程数。
addWorker(command, true)会检查线程池状态和总线程数,并确定是否创建新线程,如果创建了新线程执行这个任务,则返回true,如果没有创建新线程,则返回false。
- 尝试把任务放入任务队列,并且重新检查线程池状态,如果线程池已经不接收新的任务,则移除这个任务,并转入拒绝策略。
|
|
第二步先检查了线程池当前是否运行状态,如果是运行状态的话,则执行workQueue.offer(command)把任务放入任务队列。
任务放入队列之后,会复查线程池状态是否RUNNING,这里需要做复查的主要原因是在前面的检查中没有加锁,因此可能在添加任务队列的过程,其他线程修改了线程池的状态。
如果这个时候线程池状态被修改了,那么就会把这次添加的任务移除remove(command),同时启动拒绝策略reject(command)。
如果线程池状态没有被改变,则重新检查当前核心线程数,如果为0则调用addWorker(null, false)去队列中取任务并执行,如果不为0,则不做任何操作,等待线程执行完当前任务后自动去任务队列中获取新的任务并执行。
- 如果任务队列已满,则尝试添加临时线程,并把当然任务交给临时线程处理,如果临时线程也满了,则启动拒绝策略
|
|
这里先通过addWorker(command, false)尝试添加临时线程,如果临时线程创建成功则由临时线程执行这个任务,如果临时线程创建失败,则会返回false,并转入拒绝策略reject(command)。
addWorker
这里有一个重要的方法addWorker(Runnable firstTask, boolean core),源码如下:
|
|
addWorker首先会检查当前线程池的状态和给定的边界是否可以创建一个新的worker,在此期间会对workers的数量进行适当调整;如果满足条件,将创建一个新的worker并启动,以参数中的firstTask作为worker的第一个任务。
addWorker方法参数:
|
|
- 第一步就是检查线程池当前的状态:
|
|
如果已经不允许接受新任务了,这里就直接返回了,如果允许接受新任务的话,会继续执行
- 检查是否要求使用核心线程数为边界,如果不满足条件,则直接返回false
|
|
如果满足条件,则会执行compareAndIncrementWorkerCount(c)给计数器加1,同时跳出循环,执行下一步,如果计数器添加失败,会再次计算线程池当前状态是否RUNNING,如果线程池还在RUNNING状态,则继续重试。
- 前面已经添加了线程数了,那么下一步就开始创建新线程了:
|
|
一个Worker对象表示的是一个线程,每创建一个Worker对象,就会创建一个新的线程,并以自己作为线程的运行对象(Worker自己也是Runnable的实现类)。
- 创建了
Worker对象之后,需要对线程池做一系列的检查,并将这个对象加入到线程池中
|
|
这里首先获取线程池的主锁,保证在添加线程的过程不受其他线程干扰。
|
|
然后检查线程池状态和线程状态,如果线程池各个状态都是正常的,可以把线程加入到线程池中,则会把线程池加入线程池,并将线程添加状态设置为true:
|
|
最后释放锁:
|
|
这里要特别注意,锁一定要在finally代码块中释放,不然很容易造成死锁。
- 最后,判断线程是否已经加入线程池中,如果已经加入线程池中,则启动线程:
|
|
- 在最后判断线程是否启动,如果线程没有启动,则会做回滚:
|
|
reject
这个方法是调用线程池的拒绝处理策略:
|
|
当然这个策略可以通过我们自己传入的对象来处理,默认使用AbortPolicy处理,抛出异常。
worker线程运行
这里就涉及到Worker的run方法实现了。
|
|
这里实际上是调用了java.util.concurrent.ThreadPoolExecutor的runWorker(Worker w)方法,我们来看下这个方法:
|
|
这里首先调用Worker的unlock()方法,允许这个线程被中断,然后进入一个循环,这个循环内部做了几件事情:
- 获取要执行的任务
|
|
这里判断是否有第一个任务,如果有第一个任务则使用第一个任务,如果没有第一个任务,则使用getTask()获得新任务,getTask()是一个重要的方法,如果获取不到任务的话,这个方法会阻塞并等待任务,后边详细看这个方法。
- 获取当前线程的锁,检查当前线程是否允许运行
|
|
- 所有检查通过之后,确认当前任务可以执行了,就开始执行任务
|
|
执行任务的过程,先调用了beforeExecute(wt, task)做执行前处理,任务执行完成后,调用afterExecute(task, thrown)做执行完成后处理,这里主要是留给开发者扩展用的,默认不做任何处理,如果我们需要做一些处理,比如计算任务执行时间一类的,可以通过继承java.util.concurrent.ThreadPoolExecutor并重写这两个方法来实现。
任务执行完成后,在finally中释放了锁并给完成任务计数器加1。
getTask()
|
|
简单而言就是检查线程池状态,只要线程池还没有终止,这里就就会无限循环知道抛出异常或者线程池终止,线程的阻塞是用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)或workQueue.take()实现的。
线程池关闭
在java.util.concurrent.ExecutorService接口中提供了如下两个方法:
|
|
线程池容量的动态调整
动态调整线程池容量,在执行过程我们已经知道了,只要改变核心线程数和最大线程数即可:
|
|