LinkedHashMap 源码阅读
概要
- 类继承关系
|
|
LinkedHashMap继承自HashMap
- 核心成员变量
jdk 7:(下文都是该环境)
|
|
jdk 8:
|
|
jdk 8中新增了一个链表尾节点
- 特点
一般来说,如果需要使用的Map中的key无序,选择HashMap;如果要求key有序,则选择TreeMap。
但是选择TreeMap就会有性能问题,因为TreeMap的get操作的时间复杂度是O(log(n))的,相比于HashMap的O(1)还是差不少的,LinkedHashMap的出现就是为了平衡这些因素,使得
能够以
O(1)时间复杂度增加查找元素,又能够保证key的有序性
此外,LinkedHashMap提供了两种key的顺序:
访问顺序(access order):非常实用,可以使用这种顺序实现LRU(Least Recently Used)缓存
插入顺序(insertion orde):同一key的多次插入,并不会影响其顺序
设计原理
环型双向链表

LinkedHashMap中采用就是这种环型双向链表
LinkedHashMap结构图
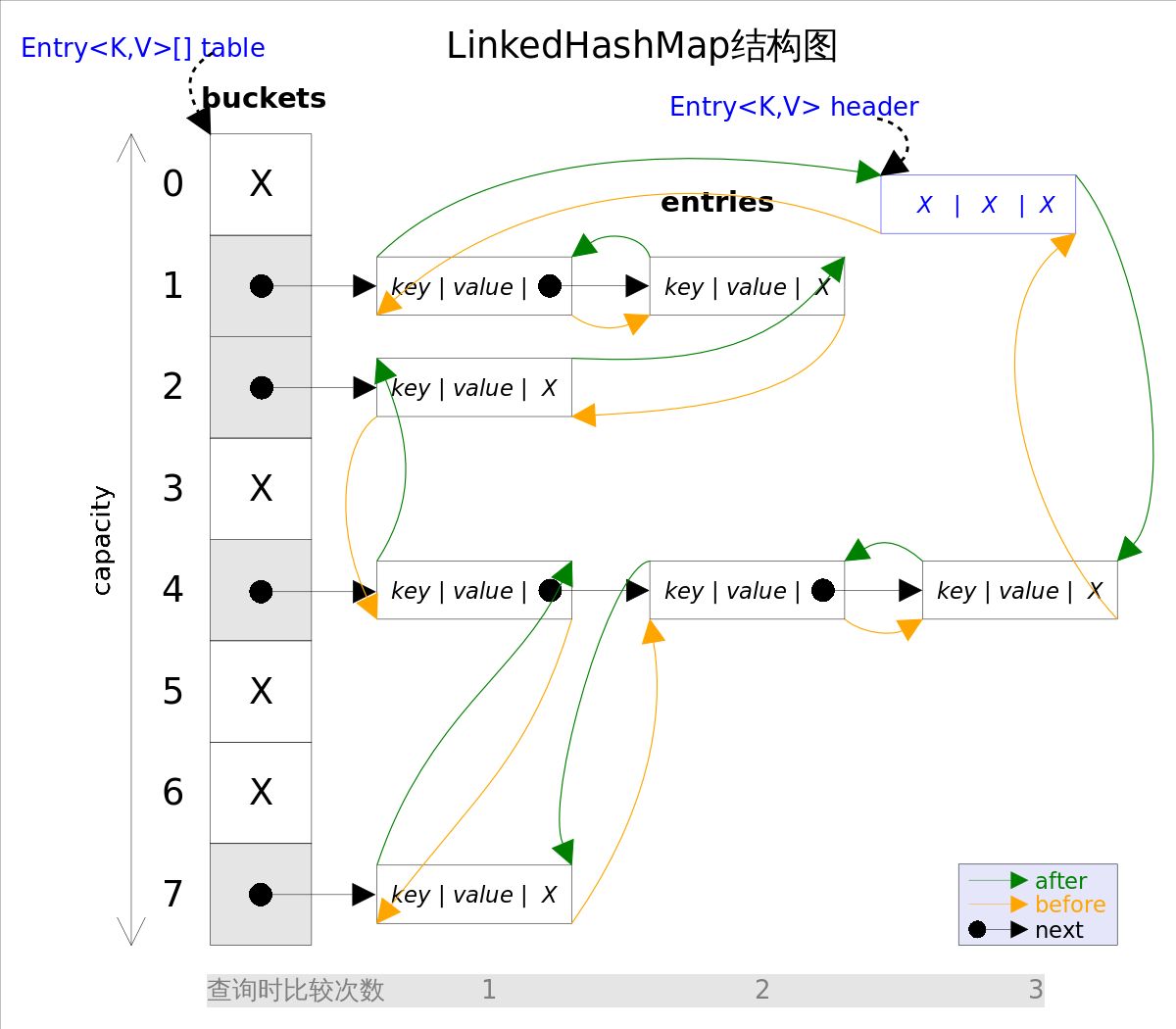
采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同;header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
源码分析
- 构造函数
|
|
- 内部节点
|
|
Entry继承自HashMap.Entry,同时增加了指向前一个和后一个节点的引用。
put方法
|
|
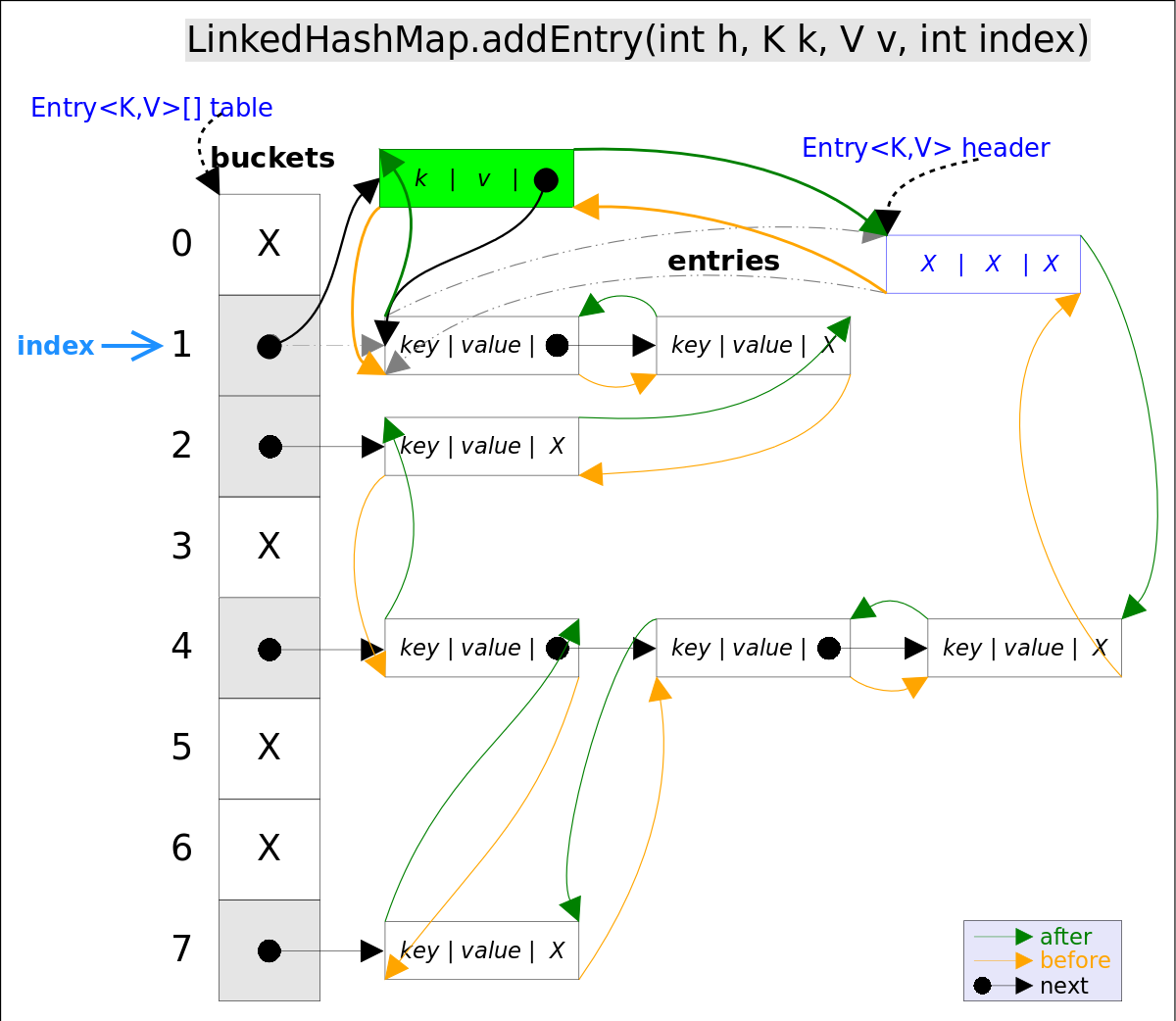
上面是LinkedHashMap中重写了HashMap的两个方法,当调用put时添加Entry(新增Entry之前不存在)整个方法调用链是这样的:
HashMap.put->LinkedHashMap.addEntry->HashMap.addEntry->LinkedHashMap.createEntry
注意,通过addEntry()方法插入新的entry,这里的插入有两重含义:
- 从
table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。 - 从
header的角度看,新的entry需要插入到双向链表的尾部。
上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。头结点代表最久未访问的节点。
get方法
|
|
LRU Cache
利用LinkedHashMap简单视线LRU cache.
|
|