安装nodejs、gulp
- 安装 nodejs
|
|
- 安装 gulp
|
|
安装gulp插件
|
|
gulp配置文件
|
|
|
|
|
|
|
|
|
|
B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树
它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图.
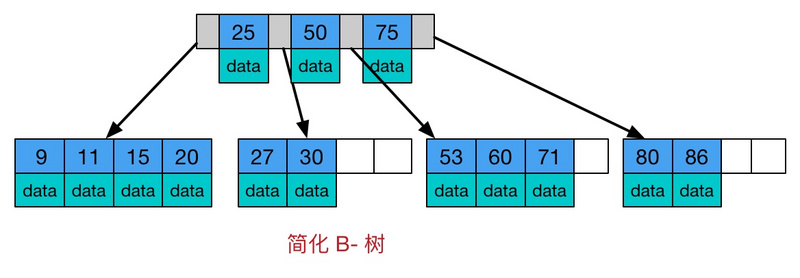
B-树有如下特点:
B+树是B-树的变体,也是一种多路搜索树, 它与B-树的不同之处在于:
所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的data)
为所有叶子结点增加了一个链指针
简化 B+树 如下图
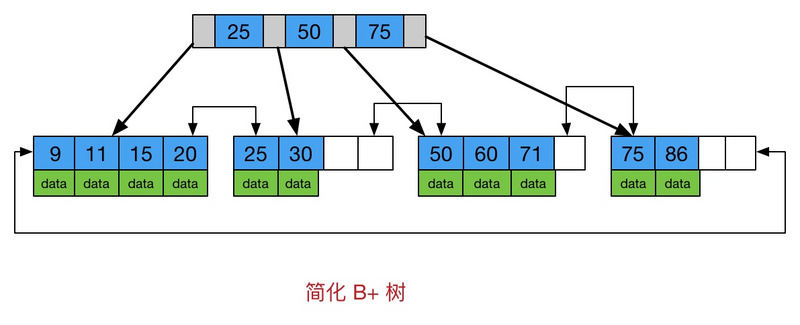
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。MySQL 是基于磁盘的数据库系统,索引往往以索引文件的形式存储的磁盘上,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
由于磁盘的存取速度与内存之间鸿沟(访问磁盘的成本大概是访问内存的十万倍左右),为了提高效率,要尽量减少磁盘I/O.磁盘往往不是严格按需读取,而是每次都会预读,磁盘读取完需要的数据,会顺序向后读一定长度的数据放入内存。而这样做的理论依据是计算机科学中著名的局部性原理:
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改).linux 默认页大小为4K(每一次IO读取的数据称之为一页)
实际实现B-Tree还需要使用如下技巧:
|
|
data域,一个结点可以存储更多的内结点,每个节点能索引的范围更大更精确,也意味着 B+树单次磁盘IO的信息量大于B-树,I/O效率更高。数据库为了维护事务的性质,尤其是一致性和隔离性,一般使用加锁这种方式。同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力。所以对于加锁的处理,可以说就是数据库对于事务处理的精髓所在。
悲观锁
正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
在悲观锁的情况下,为了保证事务的隔离性,就需要一致性锁定读。读取数据时给加锁,其它事务无法修改这些数据。修改删除数据时也要加锁,其它事务无法读取这些数据。
乐观锁
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。
乐观锁,大多是基于数据版本( Version )记录机制实现。数据版本:即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。MVCC最大的好处:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,现阶段几乎所有的RDBMS,都支持了MVCC。
在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
以MySQL InnoDB为例:
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)。
插入/更新/删除 操作,都归为当前读.如更新 操作,在数据库中的执行流程:
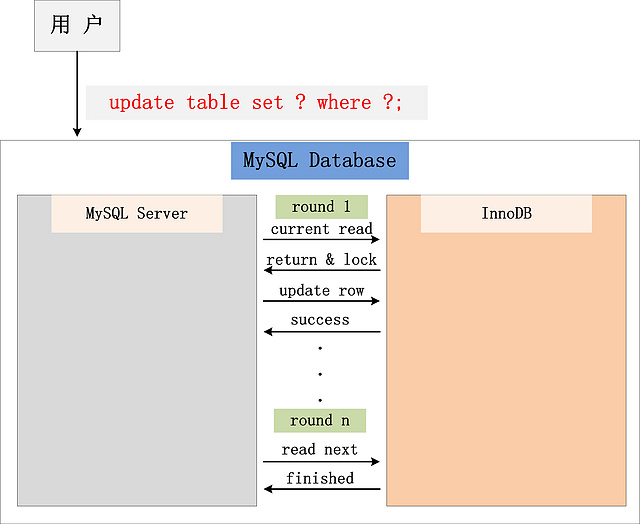
从图中,可以看到,一个Update操作的具体流程。当Update SQL被发给MySQL后,MySQL Server会根据where条件,读取第一条满足条件的记录,然后InnoDB引擎会将第一条记录返回,并加锁 (current read)。待MySQL Server收到这条加锁的记录之后,会再发起一个Update请求,更新这条记录。一条记录操作完成,再读取下一条记录,直至没有满足条件的记录为止。因此,Update操作内部,就包含了一个当前读。同理,Delete操作也一样。Insert操作会稍微有些不同,简单来说,就是Insert操作可能会触发Unique Key的冲突检查,也会进行一个当前读。
注:根据上图的交互,针对一条当前读的SQL语句,InnoDB与MySQL Server的交互,是一条一条进行的,因此,加锁也是一条一条进行的。先对一条满足条件的记录加锁,返回给MySQL Server,做一些DML操作(数据操纵语言DML:insert, update, delete);然后在读取下一条加锁,直至读取完毕。
jstack可用于导出java运用程序的线程堆栈,其基本使用语法为:
|
|
-l 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
下面这段代码运行之后会出现死锁现象(因为线程1持有lock1,在等待lock2,线程2持有lock2在等待lock1,造成了循环等待,形成死锁):
|
|
运行这段代码,然后使用jstack命令导出这个程序的线程堆栈信息:
|
|
打开导出的线程堆栈信息文件,文件末尾如下所示:
|
|
导出的线程堆栈文件中明确提示发现死锁,并且指明了死锁的原因。
jstack不仅能够导出线程堆栈,还能自动进行死锁检测,输出线程死锁原因。
jmap是一个多功能的命令。它可以生成java程序的堆dump文件,也可以查看堆内对象实例的统计信息,查看ClassLoader的信息以及Finalizer队列。
下面的命令生成PID为24205的java成粗的对象的统计信息,并输出到out.txt文件中:
|
|
生成的文件如下:
|
|
从文件中可以看到,统计信息显示了内存中实例的数量和合计。
下面的命令导出PID为24205的java程序当前的堆快照:
|
|
该命令成功地将运用程序的当前的堆快照导出到了dump.bin文件,之后可以使用Visual VM,MAT等工具分析对快照文件。
|
|