同步与异步
同步与异步主要是从消息通知机制角度来说的.
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列。
消息通知
异步的概念和同步相对。当一个同步调用发出后,调用者要一直等待返回消息(结果)通知后,才能进行后续的执行;当一个异步过程调用发出后,调用者不能立刻得到返回消息(结果),实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
执行部件和调用者通过三种途径返回结果:状态、通知和回调。使用哪一种通知机制,依赖于执行部件的实现,除非执行部件提供多种选择,否则不受调用者控制。
- 如果执行部件用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(Java Future)
- 如果是使用通知的方式,效率则很高,因为执行部件几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别(Guava Future)
阻塞与非阻塞
阻塞和非阻塞这两个概念与程序(线程)等待消息通知(无所谓同步或者异步)时的状态有关。也就是说阻塞与非阻塞主要是程序(线程)等待消息通知时的状态角度来说的。
阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务
这里的阻塞调用与同步调用容易混淆:
对于同步调用来说,很多时候当前线程可能还是激活的,只是从逻辑上当前函数没有返回而已,此时,这个线程可能也会处理其他的消息
- 非阻塞和阻塞的概念相对应,
指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。虽然表面上看非阻塞的方式可以明显的提高CPU的利用率,但是也带了另外一种后果就是系统的线程切换增加。增加的CPU执行时间能不能补偿系统的切换成本需要好好评估。
用户空间与内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
文件描述符
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
系统调用
进程想要获取磁盘中的数据,而能和硬件打交道的只能是内核,进程通知内核说我要磁盘中的数据,此过程就是系统调用。
一次I/O的完成的步骤:
当进程发起系统调用时,这个系统调用就进入内核模式,然后开始I/O操作
I/O操作分为两个步骤:
- 1、磁盘把数据装载到内核的内存空间,
- 2、内核的内存空间的数据copy到用户的内存空间中(此过程是I/O发生的地方)
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核总的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
进程获取数据的详细图解过程:
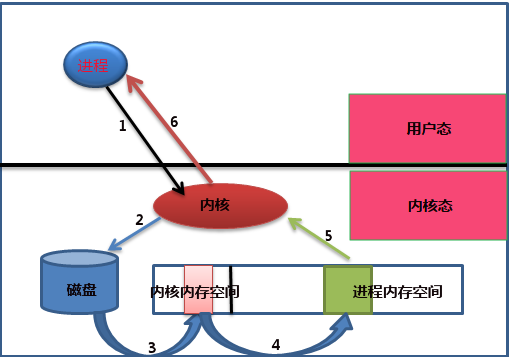
整个过程:此进程需要对磁盘中的数据进行操作,则会向内核发起一个系统调用,然后此进程,将会被切换出去,此进程会被挂起或者进入睡眠状态,也叫不可中断的睡眠,因为数据还没有得到,只有等到系统调用的结果完成后,则进程会被唤醒,继续接下来的操作,从系统调用的开始到系统调用结束经过的步骤:
①进程向内核发起一个系统调用,
②内核接收到系统调用,知道是对文件的请求,于是告诉磁盘,把文件读取出来
③磁盘接收到来着内核的命令后,把文件载入到内核的内存空间里面
④内核的内存空间接收到数据之后,把数据copy到用户进程的内存空间(此过程是I/O发生的地方)
⑤进程内存空间得到数据后,给内核发送通知
⑥内核把接收到的通知回复给进程,此过程为唤醒进程,然后进程得到数据,进行下一步操作