一、Quartz 基本介绍
1.1 Quartz特点
Quartz 具有以下特点:
- 强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求;
- 灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式;
- 分布式和集群能力,Terracotta 收购后在原来功能基础上作了进一步提升。
另外,作为 Spring 默认的调度框架,Quartz 很容易与 Spring 集成实现灵活可配置的调度功能。
quartz调度核心元素:
- Scheduler: 任务调度器,是实际执行任务调度的控制器。在spring中通过
SchedulerFactoryBean封装起来。 - Trigger:触发器,用于定义任务调度的时间规则,有
SimpleTrigger,CronTrigger,其中CronTrigger用的比较多。CronTrigger在spring中封装在CronTriggerFactoryBean中。 - JobDetail: 用来描述Job实现类及其它相关的静态信息,如Job名字、关联监听器等信息。在spring中有
JobDetailFactoryBean和MethodInvokingJobDetailFactoryBean两种实现,如果任务调度只需要执行某个类的某个方法,就可以通过MethodInvokingJobDetailFactoryBean来调用。 - Job: 是一个接口,只有一个方法
void execute(JobExecutionContext context),开发者实现该接口定义运行任务,JobExecutionContext类提供了调度上下文的各种信息。Job运行时的信息保存在JobDataMap实例中。实现Job接口的任务,默认是无状态的,若要将Job设置成有状态的,在quartz中是给实现的Job添加@DisallowConcurrentExecution注解(以前是实现StatefulJob接口,现在已被Deprecated),在与spring结合中可以在spring配置文件的job detail中配置concurrent参数。 - QuartzSchedulerResources:相当于调度的资源存放器,包含了JobStore, ThreadPool等资源,调度都是通过 QuartzSchedulerResources获取相关属性的。
实现一个最简单的 Quartz 定时任务(不支持多机),有几个步骤:
- 创建 Job。
- 创建 JobBuilder。顾名思义,可以用于生成 JobDetail 。
- 创建 TriggerBuilder。作用:配置定时时间,可以用于生成 Trigger 。
- 创建 Scheduler。作用:启动定时任务。
|
|
1.2 Quartz 集群配置
quartz集群是通过数据库表来感知其他的应用的,各个节点之间并没有直接的通信。只有使用持久的JobStore才能完成Quartz集群。
数据库表:以前有12张表,现在只有11张表,现在没有存储listener相关的表,多了QRTZ_SIMPROP_TRIGGERS表:
| Table name | Description |
|---|---|
| QRTZ_CALENDARS | 存储Quartz的Calendar信息 |
| QRTZ_CRON_TRIGGERS | 存储CronTrigger,包括Cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关Scheduler的状态信息,和别的Scheduler实例 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息 |
| QRTZ_JOB_DETAILS | 存储每一个已配置的Job的详细信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的Trigger,包括重复次数、间隔、以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger作为Blob类型存储 |
| QRTZ_TRIGGERS | 存储已配置的Trigger的信息 |
| QRTZ_SIMPROP_TRIGGERS |
QRTZ_LOCKS就是Quartz集群实现同步机制的行锁表,包括以下几个锁:CALENDAR_ACCESS 、JOB_ACCESS、MISFIRE_ACCESS 、STATE_ACCESS 、TRIGGER_ACCESS。
二、Quartz 原理及流程
2.1 quartz基本原理
Quartz是通过对用户暴露出Scheduler来进行任务的操作,它可以把任务JobDetail和触发器Trigger加入任务池中,可以把任务删除,也可以把任务停止,scheduler把这些任务和触发器放到一个JobStore中,这里jobStore有内存形式的也有持久化形式的.
它内部会通过一个调度线程QuartzSchedulerThread不断到JobStore中找出下次需要执行的任务,并把这些任务封装放到一个线程池ThreadPool中运行.
在 Quartz 中, scheduler 由 scheduler 工厂创建:DirectSchedulerFactory 或者 StdSchedulerFactory。 第二种工厂 StdSchedulerFactory 使用较多,因为 DirectSchedulerFactory 使用起来不够方便,需要作许多详细的手工编码设置。 Scheduler 主要有三种:RemoteMBeanScheduler, RemoteScheduler 和 StdScheduler。以最常用的 StdScheduler 为例讲解。
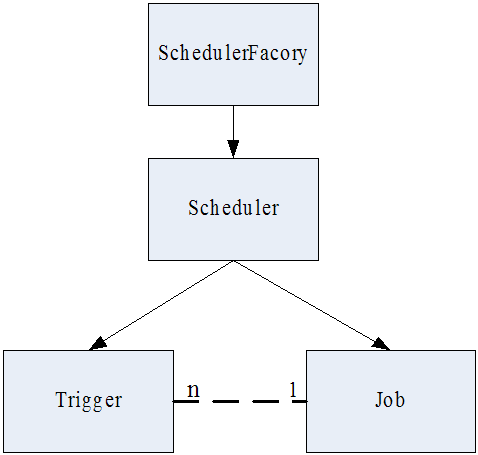
Quartz 核心元素之间的关系如下图所示:
图 1. Quartz 核心元素关系图
线程视图
在 Quartz 中,有两类线程,Scheduler 调度线程和任务执行线程,其中任务执行线程通常使用一个线程池维护一组线程。
图 2. Quartz 线程视图
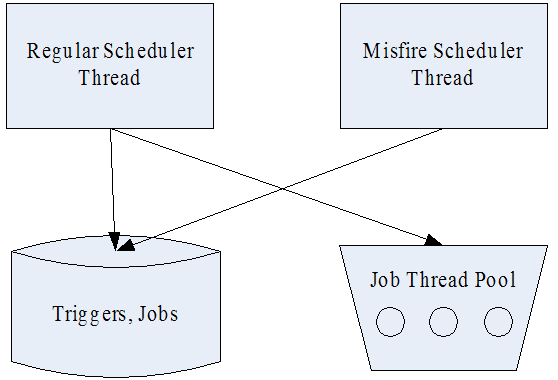
Scheduler 调度线程主要有两个: 执行常规调度的线程,和执行 misfired trigger 的线程。常规调度线程轮询存储的所有 trigger,如果有需要触发的 trigger,即到达了下一次触发的时间,则从任务执行线程池获取一个空闲线程,执行与该 trigger 关联的任务。Misfire 线程是扫描所有的 trigger,查看是否有 misfired trigger,如果有的话根据 misfire 的策略分别处理。下图描述了这两个线程的基本流程:
图 3. Quartz 调度线程流程图
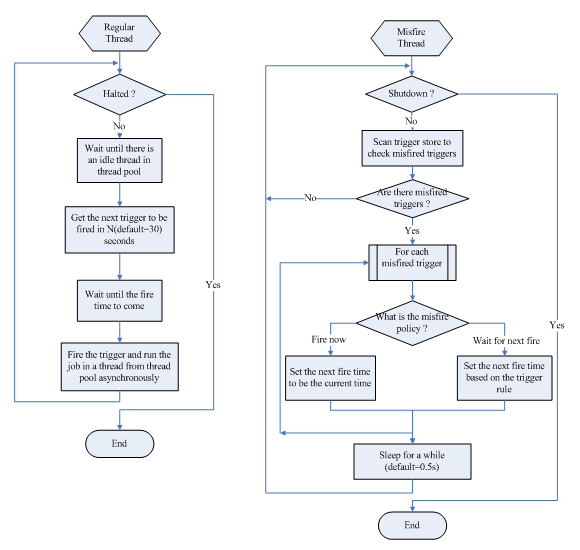
图 4. Quartz 调度执行时序图

2.2 quartz源码分析
StdSchedulerFactory.getScheduler()源码
|
|
上面有个过程是初始化jobStore,表示使用哪种方式存储scheduler相关数据。quartz有两大jobStore:RAMJobStore和JDBCJobStore。RAMJobStore把数据存入内存,性能最高,配置也简单,但缺点是系统挂了难以恢复数据。JDBCJobStore保存数据到数据库,保证数据的可恢复性,但性能较差且配置复杂。
QuartzScheduler.scheduleJob(JobDetail, Trigger)源码
|
|
QuartzScheduler.start()源码
|
|
如何采用多线程进行任务调度
QuartzSchedulerThread.java
|
|
WorkerThread.java
|
|
核心代码就是在while循环中调用Object.wait(),等待可以跳出while循环的条件成立,当条件成立时,立马调度Object.notifyAll()使线程跳出while。通过这样的代码,可以实现调度器线程等待启动、工作线程等待job等功能。