OpenJDK 源代码阅读之 ConcurrentHashMap
ConcurrentHashMap 作用
多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。虽然已经有一个线程安全的HashTable,但是HashTable容器使用synchronized(他的get和put方法的实现代码如下)来保证线程安全,在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,访问其他同步方法的线程就可能会进入阻塞或者轮训状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
Hashtable get()方法:
|
|
Hashtable put()方法:
|
|
实现原理
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
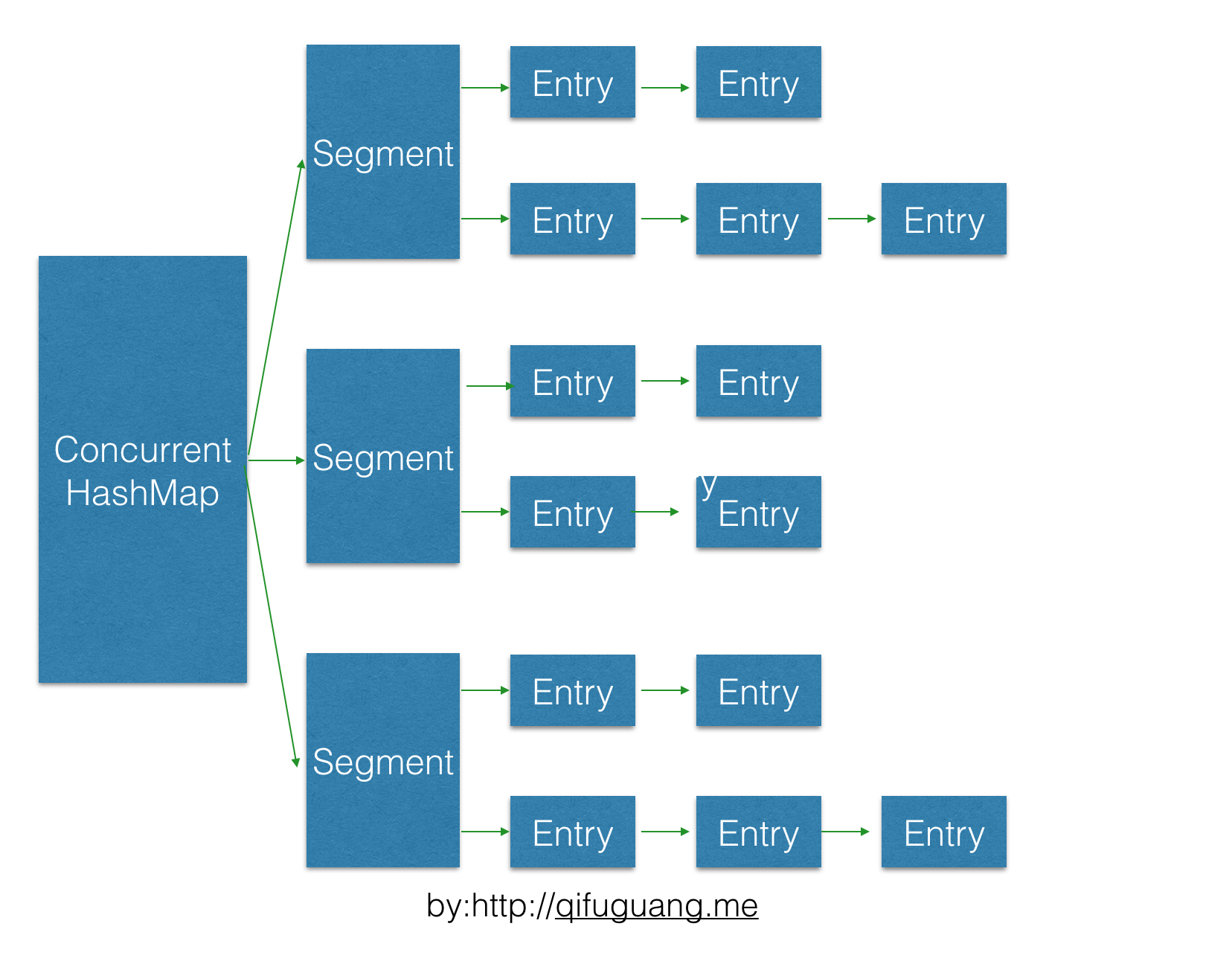
从图中可以看到,ConcurrentHashMap内部分为很多个Segment,每一个Segment拥有一把锁,然后每个Segment(继承ReentrantLock)下面包含很多个HashEntry列表数组。对于一个key,需要经过三次(为什么要hash三次下文会详细讲解)hash操作,才能最终定位这个元素的位置,这三次hash分别为:
- 对于一个key,先进行一次hash操作,得到hash值h1,也即h1 = hash1(key);
- 将得到的h1的高几位进行第二次hash,得到hash值h2,也即h2 = hash2(h1高几位),通过h2能够确定该元素的放在哪个Segment;
- 将得到的h1进行第三次hash,得到hash值h3,也即h3 = hash3(h1),通过h3能够确定该元素放置在哪个HashEntry。
初始化
构造函数的源码如下:
|
|
传入的参数有initialCapacity,loadFactor,concurrencyLevel这三个。
- initialCapacity表示新创建的这个ConcurrentHashMap的初始容量,也就是上面的结构图中的Entry数量。默认值为static final int DEFAULT_INITIAL_CAPACITY = 16;
- loadFactor表示负载因子,就是当ConcurrentHashMap中的元素个数大于loadFactor * 最大容量时就需要rehash,扩容。默认值为static final float DEFAULT_LOAD_FACTOR = 0.75f;
- concurrencyLevel表示并发级别,这个值用来确定Segment的个数,Segment的个数是大于等于concurrencyLevel的第一个2的n次方的数。比如,如果concurrencyLevel为12,13,14,15,16这些数,则Segment的数目为16(2的4次方)。默认值为static final int DEFAULT_CONCURRENCY_LEVEL = 16;。理想情况下ConcurrentHashMap的真正的并发访问量能够达到concurrencyLevel,因为有concurrencyLevel个Segment,假如有concurrencyLevel个线程需要访问Map,并且需要访问的数据都恰好分别落在不同的Segment中,则这些线程能够无竞争地自由访问(因为他们不需要竞争同一把锁),达到同时访问的效果。这也是为什么这个参数起名为“并发级别”的原因。
初始化的一些动作:
- 验证参数的合法性,如果不合法,直接抛出异常。
- concurrencyLevel也就是Segment的个数不能超过规定的最大Segment的个数,默认值为static final int MAX_SEGMENTS = 1 << 16;,如果超过这个值,设置为这个值。
- 然后使用循环找到大于等于concurrencyLevel的第一个2的n次方的数ssize,这个数就是Segment数组的大小,并记录一共向左按位移动的次数sshift,并令segmentShift = 32 - sshift,并且segmentMask的值等于ssize - 1,segmentMask的各个二进制位都为1,目的是之后可以通过key的hash值与这个值做&运算确定Segment的索引。
- 检查给的容量值是否大于允许的最大容量值,如果大于该值,设置为该值。最大容量值为static final int MAXIMUM_CAPACITY = 1 << 30;。
- 然后计算每个Segment平均应该放置多少个元素,这个值c是向上取整的值。比如初始容量为15,Segment个数为4,则每个Segment平均需要放置4个元素。
- 最后创建一个Segment实例,将其当做Segment数组的第一个元素。
put操作
put操作的源码如下:
|
|
操作步骤如下:
- 判断value是否为null,如果为null,直接抛出异常。
- key通过一次hash运算得到一个hash值。(这个hash运算下文详说)
- 将得到hash值向右按位移动segmentShift位,然后再与segmentMask做&运算得到segment的索引j。
在初始化的时候我们说过segmentShift的值等于32-sshift,例如concurrencyLevel等于16,则sshift等于4,则segmentShift为28。hash值是一个32位的整数,将其向右移动28位就变成这个样子:
0000 0000 0000 0000 0000 0000 0000 xxxx,然后再用这个值与segmentMask做&运算,也就是取最后四位的值。这个值确定Segment的索引。 - 使用Unsafe的方式从Segment数组中获取该索引对应的Segment对象。
- 向这个Segment对象中put值,这个put操作也基本是一样的步骤(通过&运算获取HashEntry的索引,然后set)。
get操作
get操作的源码如下:
|
|
操作步骤为:
- 和put操作一样,先通过key进行两次hash确定应该去哪个Segment中取数据。
- 使用Unsafe获取对应的Segment,然后再进行一次&运算得到HashEntry链表的位置,然后从链表头开始遍历整个链表(因为Hash可能会有碰撞,所以用一个链表保存),如果找到对应的key,则返回对应的value值,如果链表遍历完都没有找到对应的key,则说明Map中不包含该key,返回null。
size操作
size操作与put和get操作最大的区别在于,size操作需要遍历所有的Segment才能算出整个Map的大小,而put和get都只关心一个Segment。假设我们当前遍历的Segment为SA,那么在遍历SA过程中其他的Segment比如SB可能会被修改,于是这一次运算出来的size值可能并不是Map当前的真正大小。所以一个比较简单的办法就是计算Map大小的时候所有的Segment都Lock住,不能更新(包含put,remove等等)数据,计算完之后再Unlock。这是普通人能够想到的方案,但是牛逼的作者还有一个更好的Idea:先给3次机会,不lock所有的Segment,遍历所有Segment,累加各个Segment的大小得到整个Map的大小,如果某相邻的两次计算获取的所有Segment的更新的次数(每个Segment都有一个modCount变量,这个变量在Segment中的Entry被修改时会加一,通过这个值可以得到每个Segment的更新操作的次数)是一样的,说明计算过程中没有更新操作,则直接返回这个值。如果这三次不加锁的计算过程中Map的更新次数有变化,则之后的计算先对所有的Segment加锁,再遍历所有Segment计算Map大小,最后再解锁所有Segment。源代码如下:
|
|
举个例子:
一个Map有4个Segment,标记为S1,S2,S3,S4,现在我们要获取Map的size。计算过程是这样的:第一次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设每个Segment的大小分别为1,2,3,4,更新操作次数分别为:2,2,3,1,则这次计算可以得到Map的总大小为1+2+3+4=10,总共更新操作次数为2+2+3+1=8;第二次计算,不对S1,S2,S3,S4加锁,遍历所有Segment,假设这次每个Segment的大小变成了2,2,3,4,更新次数分别为3,2,3,1,因为两次计算得到的Map更新次数不一致(第一次是8,第二次是9)则可以断定这段时间Map数据被更新,则此时应该再试一次;第三次计算,不对S1,S2,S3,S4加锁,遍历所有Segment,假设每个Segment的更新操作次数还是为3,2,3,1,则因为第二次计算和第三次计算得到的Map的更新操作的次数是一致的,就能说明第二次计算和第三次计算这段时间内Map数据没有被更新,此时可以直接返回第三次计算得到的Map的大小。最坏的情况:第三次计算得到的数据更新次数和第二次也不一样,则只能先对所有Segment加锁再计算最后解锁。
关于hash
| 术语 | 英文 | 解释 |
|---|---|---|
| 哈希算法 | hash algorithm | 是一种将任意内容的输入转换成相同长度输出的加密方式,其输出被称为哈希值。 |
| 哈希表 | hash table | 根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上,并以关键字在地址区间中的象作为记录在表中的存储位置,这种表称为哈希表或散列,所得存储位置称为哈希地址或散列地址。 |
hash的源代码:
|
|
这里用到了Wang/Jenkins hash算法的变种,主要的目的是为了减少哈希冲突,使元素能够均匀的分布在不同的Segment上,从而提高容器的存取效率。假如哈希的质量差到极点,那么所有的元素都在一个Segment中,不仅存取元素缓慢,分段锁也会失去意义。
举个简单的例子:
|
|
这些数字得到的hash值都是一样的,全是15,所以如果不进行第一次预hash,发生冲突的几率还是很大的,但是如果我们先把上例中的二进制数字使用hash()函数先进行一次预hash,得到的结果是这样的:
|
|
可以看到每一位的数据都散开了,并且ConcurrentHashMap中是使用预hash值的高位参与运算的。比如之前说的先将hash值向右按位移动28位,再与15做&运算,得到的结果都别为:4,15,7,8,没有冲突!
注意事项
ConcurrentHashMap中的key和value值都不能为null。
ConcurrentHashMap的整个操作过程中大量使用了Unsafe类来获取Segment/HashEntry,这里Unsafe的主要作用是提供原子操作。Unsafe这个类比较恐怖,破坏力极强,一般场景不建议使用,如果有兴趣可以到这里做详细的了解Java中鲜为人知的特性
ConcurrentHashMap是线程安全的类并不能保证使用了ConcurrentHashMap的操作都是线程安全的!