OpenJDK 源代码阅读之 HashMap
概要
- 类继承关系
|
|
- 定义
|
|
- 核心成员变量
|
|
- 内部节点
|
|
- 要点
1) 与 Hashtable 区别在于:非同步,允许 null
2) 不保证次序,甚至不保证次序随时间不变
3) 基本操作 put, get 常量时间
4) 遍历操作 与 capacity+size 成正比
5) HashMap 性能与 capacity 和 load factor 相关,load factor 是当前元素个数与 capacity 的比值,通常设定为 0.75,如果此值过大,空间利用率高,但是冲突的可能性增加,因而可能导致查找时间增加,如果过小,反之。当元素个数大于 capacity * load_factor 时,HashMap 会重新安排 Hash 表。因此高效地使用 HashMap 需要预估元素个数,设置最佳的 capacity 和 load factor ,使得重新安排 Hash 表的次数下降。
实现
- capacity
|
|
注意,HashMap 并不会按照你指定的 initialCapacity 来确定 capacity 大小,而是会找到一个比它大的数,并且是 2的n次方(原因见末尾)。
- hash
|
|
如果 k 是 String 类型,使用了特别的 hash 函数,否则首先得到 hashCode,然后又对 h 作了移位,异或操作
|
|
- put
|
|
从 put 其实可以看出各个 hash 表是如何实现的,首先取得 hash 值,然后由 indexFor 找到链表头的 index,然后开始遍历链表,如果链表里的一个元素 hash 值与当前 key 的 hash 值相同,或者元素 key 的引用与当前 key 相同,或者 equals 相同,就说明当前 key 已经在 hash 表里了,那么修改它的值,返回旧值。
如果不在表里,会调用 addEntry,将这一 (key, value) 对添加进去。
|
|
可以看出,新增加元素时,可能会调整 hash 表的大小,原因之前已经讨论过。直接的添加在 createEntry 中完成,但是这里并没有体现出如何处理冲突。
|
|
注意这里,将 n 赋值给了 next,这其实就是将新添加的项指向了当前链表头。这一操作在 Entry 的构造函数中完成。
put 操作的基本思路在到这里已经很清楚了,有了这个思路,不难想象 get 是如何动作的。
|
|
和 put 差不多,只是找到了就会返回相应的 value ,找不到就返回 null。
- HashMap的底层数组长度总是2的n次方 原因:
|
|
当length为2的n次方时,h&(length - 1)就相当于对length取模,而且速度比直接取模快得多,这是HashMap在速度上的一个优化
indexFor方法,该方法仅有一条语句:h&(length - 1),这句话除了取模运算外还有一个非常重要的责任:均匀分布table数据和充分利用空间。
这里我们假设length为16(2^n)和15,h为5、6、7。
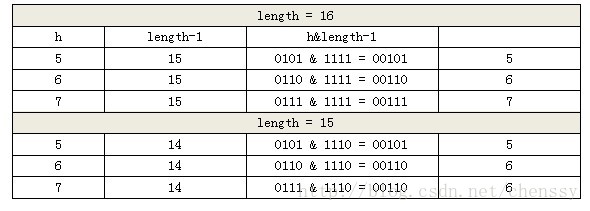
当n=15时,6和7的结果一样,这样表示他们在table存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,这样就会导致查询速度降低。诚然这里只分析三个数字不是很多,那么我们就看0-15。
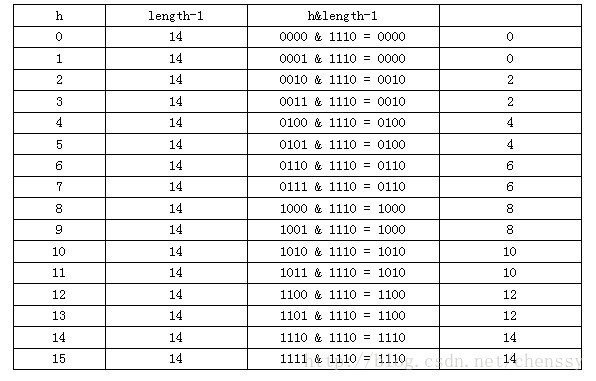
从上面的图表中看到总共发生了8此碰撞,同时发现浪费的空间非常大,有1、3、5、7、9、11、13、15处没有记录,也就是没有存放数据。这是因为他们在与14进行&运算时,得到的结果最后一位永远都是0,即0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的,空间减少,进一步增加碰撞几率,这样就会导致查询速度慢。而当length = 16时,length – 1 = 15 即1111,那么进行低位&运算时,值总是与原来hash值相同,而进行高位运算时,其值等于其低位值。所以说当length = 2^n时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。